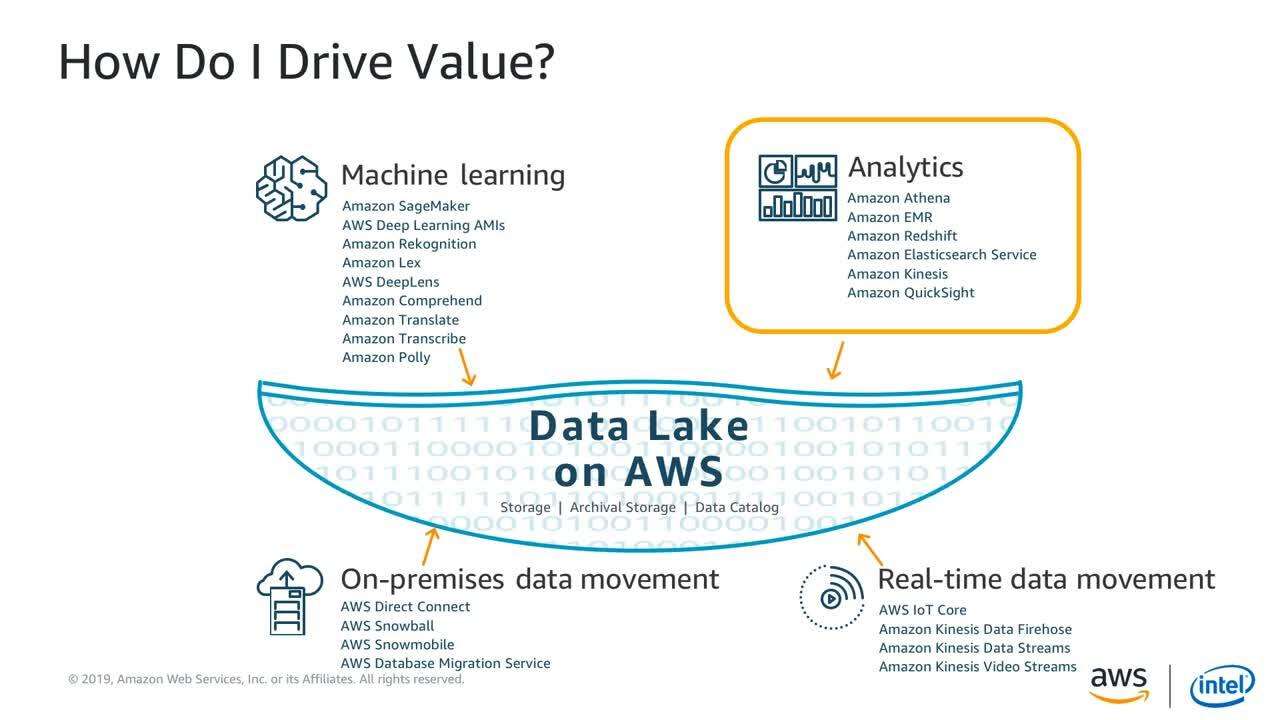
Flexibility is key when building and scaling a data lake. The analytics solutions you use in the future will almost certainly be different from the ones you use today, and choosing the right storage architecture gives you the agility to quickly experiment and migrate with the latest analytics solutions. In this session, we explore best practices for building a data lake in Amazon S3 and Amazon Glacier for leveraging an entire array of AWS, open source, and third-party analytics tools. We explore use cases for traditional analytics tools, including Amazon EMR and AWS Glue, as well as query-in-place tools like Amazon Athena, Amazon Redshift Spectrum, Amazon S3 Select, and Amazon Glacier Select.